Summary
A Python project that simulates credit scoring based on behavioral metrics and stores the results in a MySQL database. It uses a simplified version of the FICO scoring model, applying weighted factors like payment history, credit utilization, and account age. Final scores are scaled to the industry-standard 300–850 range.
Workflow
- Simulate user financial data using Python
- Calculate weighted credit factors based on real-world behavior
- Generate scaled credit scores between 300–850
- Auto-check and create database columns if missing
- Insert processed results into a MySQL database
Tech Stack
- Python – Core logic and data transformation
- Pandas – Data wrangling and metric calculations
- MySQL – Backend storage
- MySQL Connector – Python-SQL integration
- Git & GitHub – Version control and hosting
1. Input Dummy Data in Python

2. Calculation of credit score
This project calculates synthetic credit scores using Python and stores them in a MySQL database. The score is based on a simplified version of the FICO model, which is the industry standard used by lenders to evaluate credit risk.
The formula used is:
raw_score =
(payment_history * 0.35) +
(credit_utilization * 0.30) +
(credit_history_length * 0.15) +
(credit_mix * 0.10) +
(new_credit * 0.10)
Each component is computed from user-like input data and reflects real-world credit behavior:
Payment History (35%)
What it reflects: Whether the user has a history of paying on time.
How it’s calculated:
payment_history = (on_time_payments / total_payments) * 100If a user made 28 payments on time out of 30, the score is 93.3%.
Credit Utilization (30%)
What it reflects: How much of the user’s available credit is being used. Lower is better.
How it’s calculated:
credit_utilization= (credit_used / credit_limit) * 100
credit_utilization_score = 100 - credit_utilization
If someone is using 30% of their limit, they get 70% in this category.
Length of Credit History (15%)
What it reflects: How long the user has had credit.
How it’s calculated:
credit_history_length = (oldest_account_years / 10) * 100The scale is capped at 10 years for simplicity. Someone with 5 years gets 50%.
Credit Mix (10%)
What it reflects: Whether the user has different types of credit (e.g. credit cards, loans, mortgages).
How it’s calculated:
types = has_credit_card + has_loan + has_mortgage
credit_mix_score = {0: 0, 1: 50, 2: 75, 3: 100}[types]The more diverse the mix, the higher the score.
New Credit (10%)
What it reflects: Whether the user has recently opened new accounts or applied for credit.
How it’s calculated:
new_credit = max(0, 100 - (num_inquiries * 15))Each inquiry reduces the score by 15 points. Maxed at 6+ inquiries = 0%.
Scaling
After summing all weighted components, the raw score (out of 100) is scaled to match the FICO-like range of 300–850:
credit_score = 300 + (raw_score / 100) * 550This scoring system is ideal for simulation, education, or as the backend for a credit modeling web app. While simplified, it mirrors the logic of real credit algorithms in a transparent and customizable way.
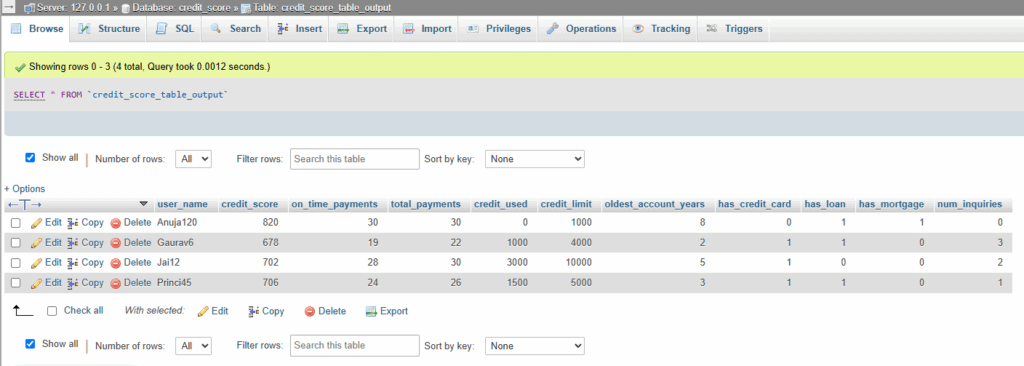
3. Output
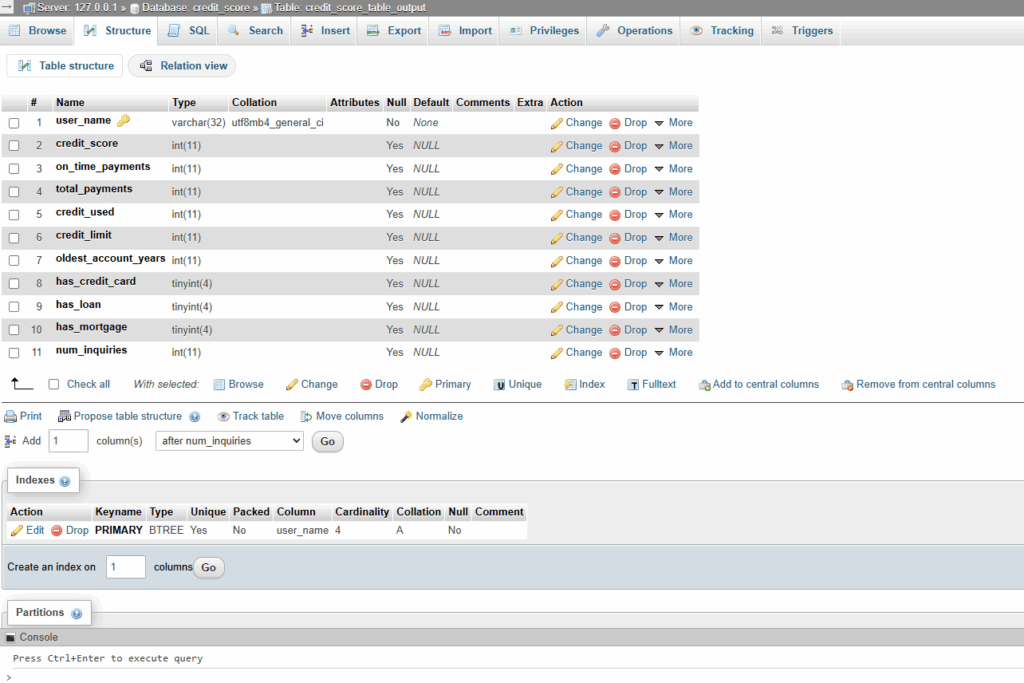
Database structure in MySQL
Output Data calculating credit score in MySQL